
1. GAN 모델 개요
GAN이란 무엇인가? GAN은 Generative Adversarial Nets이라는 논문을 통해 나온 모델로 위와 같이 진짜와 동일해 보이는 이미지를 생성하는 모델이다. 그렇다면 우선 GAN은 언제 만들어졌고 어떠한 과정을 거쳐 성장하게 되었는가? 아래는 GAN의 History를 나타내는 그림이다.
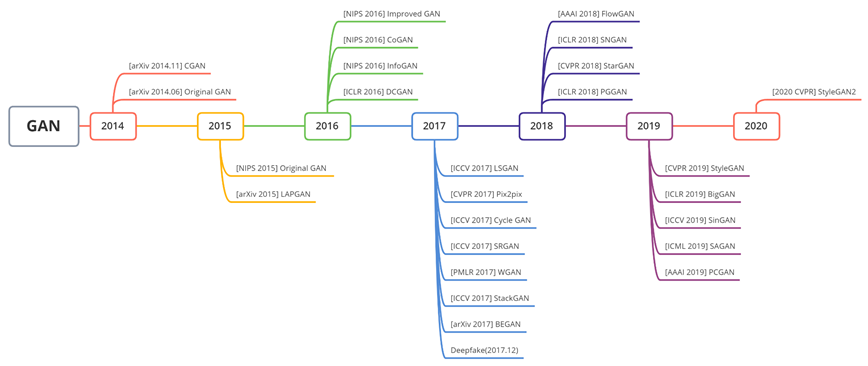
GAN은 2014년 arXive에 처음 올라온 논문이며 이후, 인공지능 관련 학회인 NIPS에서 정식으로 게재되었다. 처음 GAN 모델이 소개된 이후 수 많은 GAN의 후속 연구들이 이어지고 있는 것을 확인할 수 있다. 위 [그림 2]에 기재된 연구의 경우 대표적인 논문들을 기재한 것이며 이외에도 포함되지 않은 연구들이 여럿 존재한다.
GAN은 포스팅 되는 2021.09.14 시점으로 약 35,000회의 인용이 있는 것을 확인할 수 있고. 화두가 되었었던 Tensorflow가 발표되었던 논문보다도 더욱 많은 관심을 받고 있는 것을 확인할 수 있다.

얀르쿤(Yann LeCun)은 GAN 모델이 지난 20년간 딥러닝 분야에서 가장 멋진 아이디어라고 말한다.

그렇다면 이 GAN이라고 하는 모델은 왜 각광받고 있고 후속 연구들이 이어지고 있는 것인가?
여러 이유가 있지만 그 중 단연 핵심이라 생각되는 것은 바로 기존의 지도학습의 한계 때문이다.
기존의 지도학습의 경우 데이터셋이 필수적으로 수반된다. 하지만 이러한 데이터셋을 만드는 과정에 드는 시간 등의 비용의 한계가 있기 때문에 어렵다는 것이다. 하지만 GAN은 지도학습에 사용되는 라벨 없이도 학습 가능한 비지도학습에 속하며, 데이터를 직접 생성하는 큰 장점을 가진다. 따라서 GAN의 경우 비지도학습의 선두주자로 불리고도 있으며, 몇몇의 사람들은 비지도학습이 더욱 각광받는 기술이 될 것이라 전망한다.
아래는 처음 GAN이 나왔을 당시 논문에서 제시한 GAN 모델의 결과 중 일부이다.


왼쪽 그림은 MNIST 데이터셋을 학습하여 오른쪽 노란박스와 같이 모델이 숫자를 생성할 수 있음을 보였다. 또한 오른쪽 그림은 TFD(Torronto Faces Dataset)을 이용하여 학습한 뒤 GAN 모델이 사람의 얼굴을 생성할 수 있음을 보였다.
초기의 결과물은 색채가 없고 화질이 좋지 않았다. 하지만 GAN 모델의 단점을 극복하는 연구들이 intensive하게 진행됨에 따라 아래와 같이 진짜 이미지와 구분하기 힘들 정도로 발전하는 단계가 되었다.

우리는 여기서 이러한 GAN 모델의 성능을 발전을 가능케 했던 대표적인 연구들을 살펴보고자 한다. 이를 위한 첫 단계로 모카님의 블로그에서 아래와 같은 GAN 연구의 분류체계를 확인할 수 있었다.

모카님은 GAN을 크게 3가지로 Unconditional GAN, Conditional GAN, Super Resolution으로 나누었다. 분류체계의 기준은 어떻게 정하였는지는 잘 모르겠다. 하지만 서칭 결과 더 체계적이라 판단되는 분류체계는 찾을 수 없었다. 따라서 이를 기반으로 주요 연구들을 살펴보았다.
우리가 알아보고자 하는 대표적인 연구들은 아래와 같다.

먼저 위 연구에 대해 한마디로 정리하면 다음과 같다.
DCGAN: 얀르쿤이 GAN을 낳았다면 Facebook은 DCGAN을 통해 모든 후속연구가 이어질 수 있도록 키운 모델
LSGAN: 기존 GAN에 적용된 Loss의 수식을 Least Square loss로 바꾸어 성능 향상을 도모한 모델
PGGAN: 기존 모델과 달리 점진적으로 학습하여 1024x1024의 고화질 이미지 생성을 가능하게 한 모델
CycleGAN: 역함수 개념과 순환일관성 손실 함수를 이용해 특정 이미지의 화풍을 다른 이미지에 적용할 수 있게 한 모델
StarGAN: 단일 생성자/판별자로 Domain Transfer가 가능하도록 만든 모델
SRGAN: GAN 모델의 인지적 해상도를 높여 고화질 이미지 생성을 가능하게 한 모델
2. Original GAN
2.1 Origianl GAN의 아키텍처
먼저 GAN의 아키텍처를 확인해보면 아래의 왼쪽 그림과 같이 간단한 형태를 가진다.


GAN은 크게 2가지 모델로 이루어져 있다. Generator와 Discriminator로 이루어져 있어 동시에 두 개의 모델을 훈련하는 것이 특징이다.
여기서 z라고 하는 것은 랜덤 벡터 z를 의미하는 것으로 오른쪽 그림의 uniform distribution이나 normal distribution을 따른다고 한다.
이 랜덤 벡터 z를 Generator의 입력으로 넣어 Fake를 생성한다. 이후 Real의 경우 실제 데이터셋을 의미하는 것으로 생성된 Fake와 실제 Real 이미지를 Discriminator의 입력으로 넣게 되면 Fake 또는 Real이라고 출력하게 된다.
GAN은 최종 출력인 Fake와 Real의 확률이 1/2에 수렴하여 진짜와 가짜를 구분할 수 없도록 학습하게 된다.
GAN을 더욱 이해하기 위해서는 확률밀도함수의 개념을 알아야 한다. 아래는 어떤 모종의 확률밀도함수를 나타내는 그래프이다.
2.2 확률 밀도 함수(PDF, Probability Density Function)

먼저 확률밀도함수란 통계학에서 사용되는 개념으로, 용어에서부터 직관적으로 이해할 수 있듯 확률변수의 분포를 나타내는 것으로, 연속확률변수 x에 대한 f(x)를 의미하는 것이라 볼 수 있다.
가령 최윤제님의 발표자료에 있던 예시를 가져온 것은 아래와 같다.
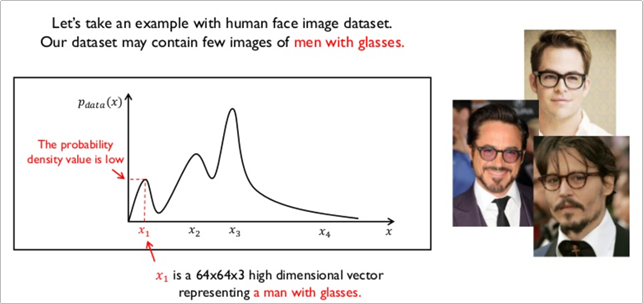
가령 GAN 모델에 안경을 낀 남성의 데이터를 학습시킨다고 할 경우, 안경을 낀 남성의 특징은 x1이라고 하는 벡터가 가지게 된다.

흑발 여성의 데이터셋을 학습 시킬 경우, 흑발 여성에 대한 특징을 x2라고 하는 벡터가 가지게 되며
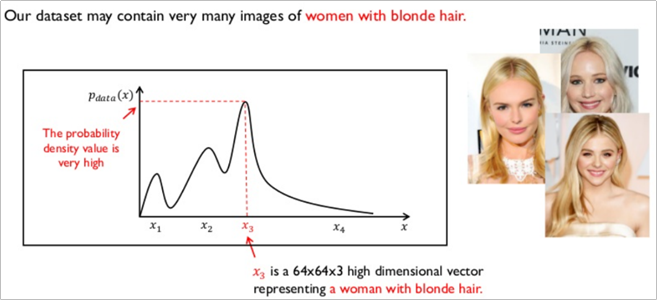
금발 여성의 데이터셋을 학습 시킬 경우 GAN 모델은 금발 여성에 대한 특징을 x3라고 하는 벡터에 학습시키게 된다.
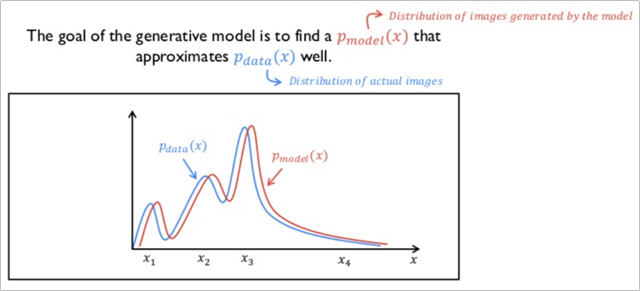
결론적으로 이렇게 학습된 확률밀도함수가 있을 때, 아래와 같이 GAN 모델이 생성한 이미지가 가지는 확률밀도함수와 둘 사이의 차이가 줄어들면 줄어들 수록 원래의 실제 이미지와 같아지는 원리라고 할 수 있다.
실제 Original GAN의 논문에 실린 그림은 아래와 같다.
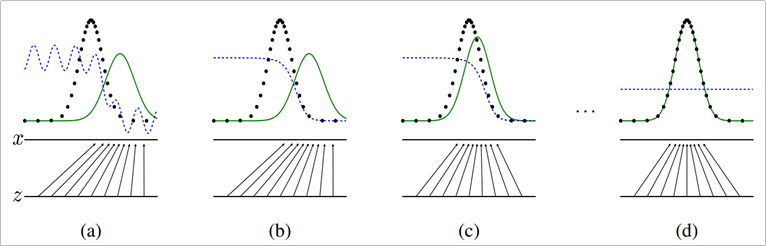
※ 검은 점선: 원 데이터의 확률분포, 녹색 점선: 생성자가 만들어 내는 확률분포, 파란 점선: 판별자의 확률분포
파란 점선인 판별자(Discriminator)는 학습이 진행됨에 따라 GAN이 만들어내는 녹색 점선(Generator)와 분포가 동일해지는 것을 확인할 수 있다.
따라서 (d)의 단계에서는 판별자가 Real/Fake를 분류하게 되어도 확률이 같기 때문에 분류를 해도 소용 없게 되며 생성자는 실제 데이터와 매우 흡사하게 이미지를 생성할 수 있게 된다.
2.3 수식으로 이해하는 GAN
GAN은 생성자와 판별자의 경쟁구도이며, 경쟁을 통해 균형점(nash equilibrium)을 찾는 것이 목표라 할 수 있다.
GAN에서 사용되는 수식은 아래와 같이 간단한 형태이다.

G(Generator)를 minimize하고 D(Discriminator)를 maximize한다고 생각하면 된다.
수식을 가장 빠르게 이해하는 방법 중 하나는 수식에 0을 만드는 요소라던지 극값을 넣어 간단한 형태로 환원시키는 것이다. 먼저 수식 내의 값들을 0으로 만들어 보자.
Case 1: D(x)를 1로 만드는 경우 (판별자가 모든 것을 분류 가능한 경우)
D(x)=1인 상황은 logD(x)를 0으로 만드려는 것과 같다. D(x)=1이라는 의미는 판별자가 모든 것을 다 올바르게 Real/Fake 분류를 할 수 있음을 의미한다. 이렇게 되면 동시에 D(G(z))=1이 된다. 그 이유는 G가 아무리 진짜와 같은 이미지를 생성하더라도 D가 100%의 확률로 전부 잡아낼 수 있기 때문이다. 결과적으로 수식의 앞 부분은 logD(x)는 0이 되어 사라지고, 뒷 부분은 log(1-1)이 되어 무한에 수렴하게 된다. (log 함수 그래프 참조)

Case 2: G(z)를 1로 만드는 경우 (판별자가 모든 것을 분류하지 못하는 경우)
G(z)=1인 상황은 생성자 G가 실제와 구분하지 못할 정도로 흡사하게 만들어 판별자 D가 하나도 구분하지 못하는 상황과 같다. 이렇게 되면 수식의 앞 부분인 logD(x)는 log0이 되어 무한에 수렴하게 되고, 뒷 부분인 log(1-D(G(z))는 0이 되어 사라지게 된다. (이 상황의 경우 minmax요소가 바뀜. min→D, max→G)
2.4 코드로 이해하는 GAN
GAN의 수식을 코드로 표현할 경우 아래와 같아진다.
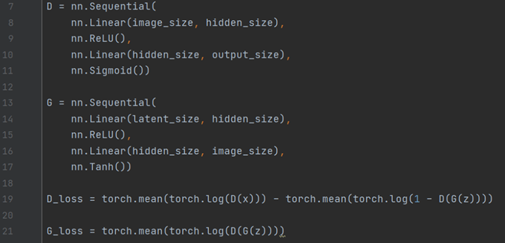
크게 4 영역으로 판별자 D의 layer, 생성자 G의 layer, D의 loss, G의 loss 부분으로 나뉜다. 핵심은 loss를 표현하는 영역으로 앞서 설명한 수식을 이용하여 위와 같이 작성할 수 있다.
2.5 실험 결과
결과적으로 앞서보았던 그림을 포함하여 크게 3종류인 (MNIST, TFD, CIFAR-10)의 데이터셋에 대해 학습하고 이를 생성자 모델을 사용하여 시각화 하는 것을 확인할 수 있다.

숫자와 얼굴의 경우 어느정도 식별 가능한 형태라 볼 수 있으며, 동물/사물에 대해서는 비교적 추상적으로나마 생성해내는 것을 확인할 수 있다.
2.6 한계점
기존의 GAN의 한계점은 크게 2가지로 나뉜다.
1. (성능 평가)
GAN 모델의 성능을 객관적 수치로 표현할 수 있는 방안이 부재했다. GAN의 경우 결과 자체가 새롭게 만들어진 데이터이기 때문에 비교 가능한 정량적 척도가 없었다는 것이다.
2. (성능 개선)
GAN은 기존 네트워크 학습 방법과 다른 구조여서 학습이 불안정했다. GAN은 Saddle Problem 혹은 Minmax를 풀어야 하는 태생적으로 불안정한 구조이기 때문이다.
실제 2016년 NIPS에서도 GAN의 안정화가 메인화두였다고 한다.
하지만 이의 두 단점을 모두 개선하여 GAN의 후속 연구가 줄줄이 이어나올 수 있도록 한 연구가 Facebook에서 개발한 DCGAN(Deep Convolutional GAN)이다.
'Deep Learning > pytorch' 카테고리의 다른 글
| CycleGAN (0) | 2023.08.14 |
|---|---|
| SRGAN (Super Resolution GAN) (0) | 2023.08.14 |
| PGGAN (Progressive Growing GAN) (0) | 2023.08.14 |
| LSGAN (Least Square GAN) (0) | 2023.08.14 |
| DCGAN (Deep Convolutional GAN) (0) | 2023.08.14 |