1. SRGAN (Super Resolution GAN)
SRGAN은 Super Resolution GAN을 의미하는 것으로 한마디로 말하여 저화질의 이미지를 고화질의 이미지로 바꾸는 모델이라 할 수 있다.
1.1 연구 배경
기존의 SR 모델에서 목적 함수를 MSE (Mean Square Error)로 학습하여 높은 PSNR (Peak Signal-to-Noise Ratio)를 가진다. 하지만 High Frequency 성분을 갖는 detail이 결여되어 있기 때문에 Texture를 표현하는 것이 어렵다는 점을 극복하기 위해 진행 된 연구이다.

[그림 37] SRGAN과 타 모델 간의 성능 비교
쉽게 말해 MSE는 이미지가 조금 흐릿한 형태를 띠게 되는데 이는 MSE loss function은 average(평균제곱오차)를 학습하기 때문이다. 전반적으로 smooth한 정보를 얻어서 high frequency content를 표현하지 못한다는 것이다. 다시 말해 평균을 loss로 잡았기 때문에 이미지의 고주파수 영역이 평균 값으로 회귀 된다는 의미이다.
1.2 PSNR
먼저 PSNR을 설명하면, 최대 신호대비 잡음비라고 할 수 있다. 구체적으로, 신호가 가질 수 있는 최대 전력에 대한 잡음의 전력이다. 주로 동영상이 압축될 때 화질 손실 정보를 평가할때 사용하는 지표로, 높을 수록 결과 값이 좋다 할 수 있다.

[그림 38] PSNR 수치 저하에 따른 이미지 화질 비교
하지만 이러한 PSNR의 단점은 원본 이미지와 왜곡 이미지 사이의 수치적 차이로 평가하기 때문에 사람 인지와 일치되지 않는 품질 점수를 산출한다는 것이다. 예를 들면 아래 그림과 같다.

[그림 39] 비슷한 PSNR 수치에 대한 인지적 품질의 차이
PSNR 값은 유사하지만 품질을 제대로 반영하지 못하는 것과 같다. 이는 PSNR을 산출하는 수식에 내재한 단점이라 볼 수 있다.

[그림 40] PSNR 산출 수식
핵심은 맨 아랫줄만 확인하면 이해할 수 있다. PSNR은 MAX에 log scale을 취한 것에 MSE에 log scale을 취한 것을 빼준다. 하지만 앞서 언급하였던 MSE를 사용하기 때문에 이미지의 고주파수 영역을 나타내지 못하고 결과적으로 PSNR 값에 따른 이미지의 품질이 사람의 인지와 달라지는 것이다.
이러한 단점을 극복하기 위해 대안으로 사용하는 것은 SSIM, MOS, PSNR-HVS, PSNR-HVS-M, VIF 등이 있긴하다.

[그림 41] PSNR의 대안인 SSIM (1에 가까울 수록 좋음)
하지만 다시 SRGAN 모델로 돌아와서, 결과적으로 이 연구에서 하고자 하는 핵심은 해상도를 평가하는 PSNR이라는 수치는 높더라도 실제 사람의 눈으로 봤을 때 해상도가 높지 않다. 따라서 실제로 눈으로 보더라도 해상도가 높게 나올 수 있도록 만들겠다는 것이 이 연구의 핵심이라 할 수 있다.
1.3 연구 핵심
위와 같은 단점을 해결하기 위한 핵심 방안으로, 인지적 유사성에 주목한 perceptual loss를 사용하였다는 것이다. percepual loss는 크게 2가지인 content loss와 adversarial loss로 구성된다.
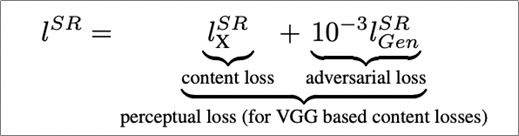
[그림 42] perceptual loss
5.3.1 content loss
pixel space에서 유사성 대신에 perceptual 유사성을 학습하기 위한 loss이다.

[그림 43] content loss
복잡할 것 없이 간단하게 이해하면 다음과 같다. LR(Low Resolution) 이미지를 즉, 저해상도 이미지를 생성자가 만들면 판별자가 판별할 것인데 N개를 판별한 합이 작아지도록 만드는 것이라 할 수 있다.
1.3.2 Adversarial loss
판별자를 속이기 위한 loss 함수라 할 수 있다.
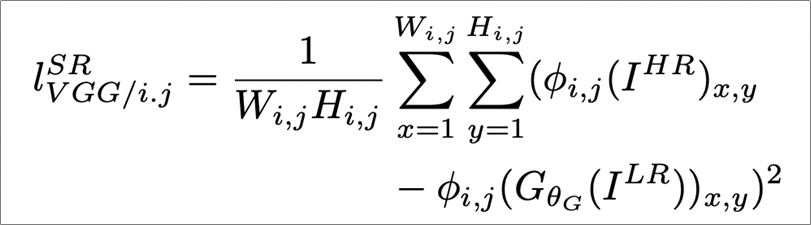
[그림 44] adversarial loss
쉽게 간략히만 이해하면 HR(고해상도)의 이미지에서 LR(저해상도)의 이미지를 빼고 제곱을 취해준 값의 합이 점점 줄어들도록 학습하는 것이라 볼 수 있다.
1.4 아키텍처
논문에 언급된 아키텍처보다 더 직관적으로 설명되어 있는 그림을 확인할 수 있었고 아래와 같다.

[그림 45] SRGAN 아키텍처
Pretrained된 2개의 VGG net loss를 사용한다. (reconstructed image와 reference image의 feature map 사이의 유클리디안 거리를 계산하는 방법을 사용) 여기에서 사용된 VGG22는 low level feature map을 대표하는 loss이며, VGG54는 high level feature map을 대표하는 loss라고 할 수 있다.
1.5 실험결과
평가 방법 중 MOS (Mean Opinion Score)를 사용하였는데 이는 Perceptual Quaility를 표현하기 위함이다.

[그림 46] SRGAN 모델 성능 지표 비교
Set5와 Set14의 경우 데이터셋을 의미한다. 저자들은 MOS라고 하는 벤치마크 스코어를 사용하여 MSE를 사용하였을 때 보다 높은 MOS 스코어를 얻음을 보인다. 하지만 MOS라고 하는 것은 일종의 주관적인 평가로, 평가자 몇 명을 모집하여 사용하는 방식이라는 점에 있어서 정량적이라기 보다 정성적인 평가에 가깝다고 볼 수 있다.
주요 컨트리뷰션 포인트로는 크게 2가지로, 첫번째는 새로운 perceptual loss를 제안하였다는 점이고 두 번째로는 모호하지만 새로운 벤치마크 스코어인 MOS를 제안하였다는 것이다.
참고로 VGG54를 저자들은 SRGAN이라고 부른다.
1.6 적용 결과
저자들은 유튜브에 자신들이 만든 SRGAN을 이용한 영화 화질을 높이는 것을 보였다.
1.7 국내 연구 사례


[그림 47] SRGAN 국내 연구 사례
또한 이러한 SRGAN을 사용하여 CCTV 영상의 화질을 개선하는 기법을 연구한 국내 연구 사례도 존재한다. 하지만 그럴듯하게 생성이 가능하다는 것이지 법적인 증거로서의 효력으로 채택되는 것은 별 개의 문제가 될 수 있겠다.
'Deep Learning > pytorch' 카테고리의 다른 글
| [Pytorch] 장치간 모델 불러오기 (GPU / CPU) (0) | 2023.08.17 |
|---|---|
| CycleGAN (0) | 2023.08.14 |
| PGGAN (Progressive Growing GAN) (0) | 2023.08.14 |
| LSGAN (Least Square GAN) (0) | 2023.08.14 |
| DCGAN (Deep Convolutional GAN) (0) | 2023.08.14 |