GYM 튜토리얼 & Model-Based 강화학습
강화학습을 공부하기 위해 제공되는 환경 라이브러리로 GYM이 있습니다. 해당 라이브러리를 사용하여 MountainCar문제를 풀어보겠습니다.
실습 환경
OpenAI Gym

Gym은 OpenAI재단에서 강화학습을 학습하기 위해 만든 환경으로서, 강화학습의 표준 환경이라고 볼 수 있습니다. 강화학습 알고리즘들을 비교하고, 테스트를 해 볼 수 있는 학습 도구입니다. 해당 환경은 학습을 위한 용도로 사용되며, 강화학습을 실생활에 응용하고 적용하기 위해서는 환경 자체를 새로 설계하여야합니다.
import gym- Gym 홈페이지: https://gym.openai.com/
- Gym Github: https://github.com/openai/gym
Colab 실습환경
!pip install gym pyvirtualdisplay
!apt-get install -y xvfb python-opengl ffmpeg
!apt-get update
!apt-get install cmake
!pip install --upgrade setuptools
!pip install ez_setup
!pip install gym[atari]
!pip install box2d-py
!pip install gym[Box_2D]강화학습 튜토리얼 (신경망 모델 사용)
강화학습의 여러 방법론중에 기초적으로 먼저 신경망 모델을 사용하여 수행해보겠습니다. 신경망 모델은 아래의 MountainCar라는 예제를 통해 진행하겠습니다.
MountainCar

- 구성요소
- Environment : 언덕, 해당 언덕은 왼쪽과 오른쪽을 반복하여 가속도를 만들어야 언덕을 오를 수 있는 환경입니다.gym라이브러리의 make메소드를 통해서 환경을 생성할 수 있습니다.
- observation_space : 관찰 공간, Agent가 환경을 볼 수 있는 범위를 의미합니다. 해당 공간에서만 정보를 얻을 수 있습니다. 이 관찰공간에서 low는 x축 좌표의 최솟값과, 최소 속도입니다. high는 x축 좌표의 최댓값과 최대 속도를 보여줍니다.
- max_episode_steps : 각 에피소드마다의 종료 조건을 의미합니다.해당 값이 n이라면, 최대 n번의 time step을 가지고 n번 움직이면 종료된다는 것을 의미합니다.
- env = gym.make('MountainCar-v0') print(env.observation_space) print(env.observation_space.low) print(env.observation_space.high) print(env._max_episode_steps)
- Agent : 자동차
- Action : '왼쪽', '정지', '오른쪽'
- action_space : 행동 공간, Agent가 할 수 있는 행동의 경우의 수를 의미합니다. Discrete는 이산적이라는 뜻으로, 정수로 나눌 수 있다는 것을 의미합니다. 해당 환경에서는 Discrete(3)으로 '왼쪽'(0), '정지'(1), '오른쪽'(2) 총 3가지 행동이 가능합니다.
- print(env.action_space)
- Reward : 200이하의 step에서, time step 마다 -1, 깃발(x축 0.5 지점)에 도착하는 것(종료 조건, 최대 보상 조건)이 목표입니다.
- Environment : 언덕, 해당 언덕은 왼쪽과 오른쪽을 반복하여 가속도를 만들어야 언덕을 오를 수 있는 환경입니다.gym라이브러리의 make메소드를 통해서 환경을 생성할 수 있습니다.
- 기본적인 학습 코드
- 변수 선언 및 env.reset()을 통하여 환경 초기화를 합니다.
- gym.make를 통해서 해당 환경을 생성합니다. env.render()라는 메소드를 통해서 에피소드 실행 결과를 화면으로 출력할 수 있습니다. (Colab에서는 안됩니다.)
- Colab의 경우 아래의 메소드들을 사용하여 영상 mp4파일로 확인가능합니다.
- # env.render() 함수의 결과를 mp4 동영상으로 보여주기 위한 코드 # from https://colab.research.google.com/drive/1flu31ulJlgiRL1dnN2ir8wGh9p7Zij2t from gym import logger as gymlogger from gym.wrappers import Monitor gymlogger.set_level(40) #error only import glob import io import base64 from IPython.display import HTML from IPython import display as ipythondisplay """ Utility functions to enable video recording of gym environment and displaying it To enable video, just do "env = wrap_env(env)"" """ def show_video(): mp4list = glob.glob('video/*.mp4') if len(mp4list) > 0: mp4 = mp4list[0] video = io.open(mp4, 'r+b').read() encoded = base64.b64encode(video) ipythondisplay.display(HTML(data='''<video alt="test" autoplay loop controls style="height: 400px;"> <source src="data:video/mp4;base64,{0}" type="video/mp4" /> </video>'''.format(encoded.decode('ascii')))) else: print("Could not find video") def wrap_env(env): env = Monitor(env, './video', force=True) return env from pyvirtualdisplay import Display display = Display(visible=0, size=(1400, 900)) display.start()
- 아래와같이 wrap_env로 기존 환경을 Monitor하도록 설정후, show_video()를 통해서 확인 가능합니다.
- env = gym.make('MountainCar-v0') env = wrap_env(env) # 코드 작성 env.close() show_video()
- env = gym.make('MountainCar-v0') # env.render() env.reset() step = 0 score = 0
- 변수 선언 및 env.reset()을 통하여 환경 초기화를 합니다.
- 반복문 안에서, sample()을 진행합니다. 랜덤한 action을 수행합니다. 0, 1, 2 세가지 경우 중에 하나가 랜덤으로 리턴됩니다.
- 반복문 안에서, step을 진행합니다. env.step마다 action이 전달되어 Agent가 행동합니다. 이때 리턴 값들은 각각 obs(환경이 바뀐 상태), reward(보상), done(에피소드 종료 여부), info(기타 정보들)이 전달됩니다.
- 이때의 보상을 score에 더하여 step마다 score를 출력합니다.
- while True: action = env.action_space.sample() obs, reward, done, info = env.step(action) score += reward step += 1 if done: break
- step시 마다 전달되는 done을 통하여 step이 모두 진행되었는지 또는 에피소드가 끝났는지를 파악합니다. done이 True가 되면, 반복문을 벗어나고 최종 score와 step을 출력합니다.
- print('Final Score : ', score) print('Step : ', step)
- env.close()를 통해 종료를 선언하고, show_video()함수를 통해 에피소드 실행 결과를 mp4파일로 화면에 출력합니다.
- env.close() show_video()

- 문제를 해결하는 코드

- 세가지의 큰 순서로 진행됩니다.
- 학습 데이터 생성
- 모델 생성 및 학습
- 행동 예측 및 수행
- 학습 데이터 생성
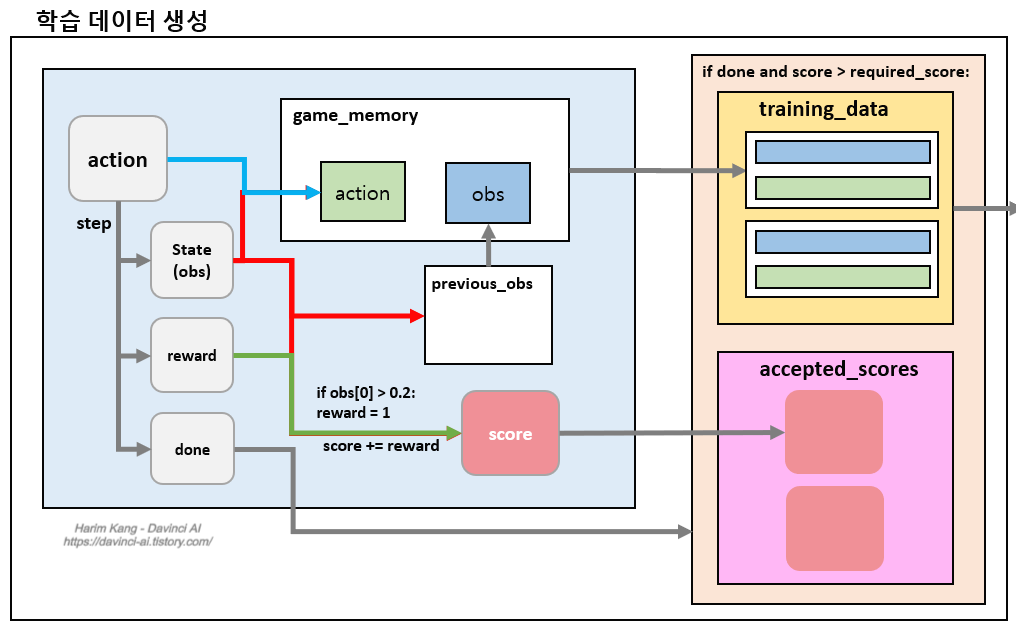
- 앞서 수행한 랜덤적인 방법을 반복적으로 수행하여 지정한 required_score보다 높은 점수를 얻은 행동들을 저장하는 방법으로 학습 데이터를 생성합니다.
- 한 시나리오의 score가 지정한 기준보다 높은 경우 game_memory에 저장해놓은 action들을 학습데이터로 쓰기 위하여 training_data에 저장합니다.
- 20000번 반복하여 -198이상의 점수를 얻은 행동을 학습 데이터로 만듭니다.

- %tensorflow\_version 2.x import tensorflow as tf import gym import random import numpy as np env = gym.make('MountainCar-v0') scores = \[\] training\_data = \[\] accepted\_scores = \[\] required\_score = -198 for i in range(20000): env.reset() score = 0 game_memory = [] previous_obs = [] while True: action = env.action_space.sample() obs, reward, done, info = env.step(action) if len(previous_obs) > 0: game_memory.append([previous_obs, action]) previous_obs = obs if obs[0] > -0.2: reward = 1 score += reward if done: break scores.append(score) if score > required_score: accepted_scores.append(score) for data in game_memory: training_data.append(data) print('finished!') print('mean of scores', np.mean(scores)) print('length of acceted_scores', len(accepted_scores)) print('mean of acceted_scores', np.mean(accepted_scores))
- 전체 경우에 대해서는 평균 -199점을 얻습니다. 기준 이상의 점수들은 100번 나왔고, 모아서 평균을 구하면 -180정도가 나왔습니다.
- 모델 생성 및 학습
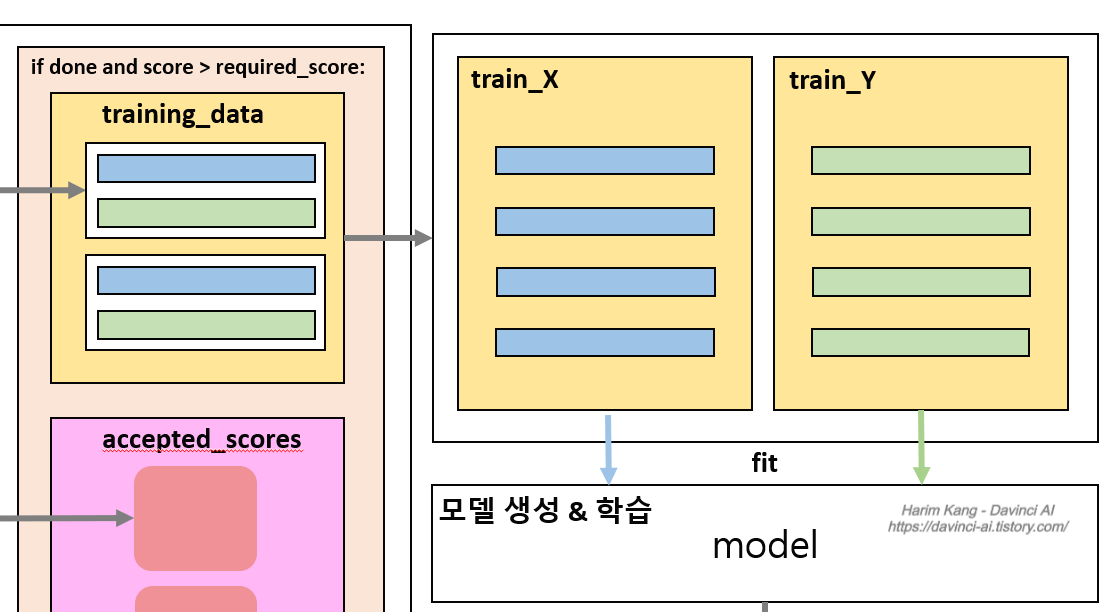
- 상태를 의미하는 obs를 train_X 데이터로, 그에 따른 행동(action)을 train_Y로 분리해줍니다.
- train_X = np.array([i[0] for i in training_data]).reshape(-1, 2) train_Y = np.array([i[1] for i in training_data]).reshape(-1, 1)
- model을 생성하여 학습을 시켜줍니다. 이때 모델은 action을 예측하는 모델입니다. 그러므로 -1, 0, 1로 이루어진 값을 예측하여야합니다. 이때, 분류(Classification) 모델을 사용합니다.
- Dense 레이어로 이루어진 Sequential모델을 선언해줍니다. 마지막 층은 softmax를 통해서 action 3가지 중 하나를 예측하도록 선언해주었습니다.
- 저는 Early Stopping을 사용하여 5번 이상 validation loss 값이 상승하면 훈련을 멈추도록 하였습니다.
- 또한, 과적합을 방지하기 위해, 데이터의 25%를 validation data로 사용하였습니다.
- model = tf.keras.Sequential([ tf.keras.layers.Dense(128, input_shape=(2,), activation='relu'), tf.keras.layers.Dense(32, activation='relu'), tf.keras.layers.Dense(3, activation='softmax') ]) model.compile(optimizer=tf.optimizers.Adam(), loss='sparse_categorical_crossentropy', metrics=['accuracy']) callback = tf.keras.callbacks.EarlyStopping(monitor='val_loss', patience=5) history = model.fit(train_X, train_Y, epochs=30, callbacks=[callback], batch_size=16, validation_split=0.25)
- 학습 결과를 확인합니다.
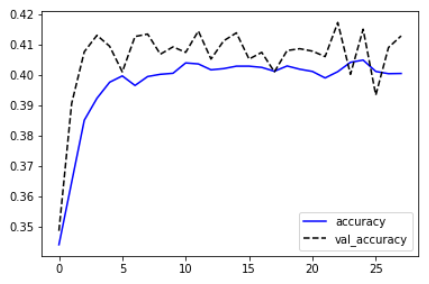
- import matplotlib.pyplot as plt plt.plot(history.history['accuracy'], 'b-', label='accuracy') plt.plot(history.history['val_accuracy'], 'k--', label='val_accuracy') plt.legend() plt.show()
- 행동 예측 및 수행

- 학습된 모델을 사용하여 다음 행동을 예측하여 시나리오를 수행해보겠습니다.
- 시작은 랜덤 값으로 action을 받고, 그 이후에는 이전의 상태를 model에 예측하도록 값을 전달합니다. 예측된 action을 사용하여 env.step을 이용하여 다음 순서를 수행합니다.
- 이때의 점수와 스텝 수를 확인하면 아래와 같습니다. (model마다, 예측마다 결과는 다르게 나옵니다.)


- env.close() env = wrap_env(gym.make('MountainCar-v0')) env.reset() score = 0 step = 0 previous_obs = [] while True: if len(previous_obs) == 0: action = env.action_space.sample() else: logit = model.predict(np.expand_dims(previous_obs, axis=0))[0] action = np.argmax(logit) obs, reward, done, _ = env.step(action) previous_obs = obs score += reward step += 1 if done: break print('score : ', score) print('step : ', step) env.close() show_video()
- 학습된 모델을 사용하여 다음 행동을 예측하여 시나리오를 수행해보겠습니다.
- 세가지의 큰 순서로 진행됩니다.
- 위의 기본적인 학습 코드로는 에피소드를 단순하게 랜덤적으로 수행합니다. 도착점에 도달하기에는 힘들어보입니다. 해당 포스팅에서는 신경망을 사용하여 학습을 위해서는 괜찮은 에피소드들을 추려서 저장해놓은 다음에, 해당 데이터를 신경망에 학습하는 방법을 사용해보겠습니다. 아래의 그림과 같은 순서로 진행됩니다.
기존 신경망의 한계
위의 방식처럼 분류 신경망 모델을 사용하여 행동이 이산적인(왼쪽, 정지, 오른쪽) 코드에서는 잘 동작합니다. 하지만, MountainCarContinuous-v0라는 연속적인 행동 값(실수)으로 풀어야하는 문제에서는 회귀 신경망 모델 사용하여 시도하여야합니다. 하지만 해당 모델은 관찰 상태에 대한 적절한 행동을 찾아내지 못합니다. 이러한 경우에는 Q-Learning이라는 관찰 상태에서 취할 수 있는 모든 행동의 Q값을 학습하는 방법을 사용하여 풀어낼 수 있습니다. 다음 포스팅에서는 Q 러닝에 대해서 학습해 보겠습니다.
해당 포스팅의 실습 코드는 아래 깃허브 주소에서 확인하실 수 있으며, colab 환경에서 작성하였습니다.
https://github.com/harimkang/tensorflow2_deeplearning/blob/master/reinforcement.ipynb